In the era of rapid advancements in artificial intelligence, tools like Large Language Models (LLMs) have revolutionized content creation, but they’ve also posed significant challenges to academic integrity. Turnitin, a leader in plagiarism detection and academic tools, has developed sophisticated AI writing detection systems to help educators identify AI-generated content. This blog post delves into the mechanisms behind Turnitin’s AI detection, drawing from their August 2024 white paper titled “Turnitin’s AI Writing Detection Model Architecture and Testing Protocol” (Turnitin AI Technical Staff, 2024). We’ll explore the core concepts, model architecture, testing protocols, and performance metrics, providing an introductory overview for educators, students, and tech enthusiasts.
The Rise of Generative AI and Its Impact on Education
Writing remains a fundamental skill in education, fostering critical thinking, creativity, and narrative development. However, the advent of generative AI, particularly LLMs, has disrupted this landscape. LLMs, such as those from OpenAI (2023), can produce novel text from natural language prompts, differing from earlier models like sequence-to-sequence translators (Sutskever et al., 2014). These models trace their roots to the transformer architecture introduced by Vaswani et al. (2017), which enables deep associations between text tokens (words or subwords).
Trained on vast internet datasets, LLMs with billions of parameters—such as PaLM (Chowdhery et al., 2022) or GPT-4 (OpenAI, 2023)—exhibit emergent behaviors, performing complex tasks akin to human reasoning (Wei et al., 2022; Hagendorff, 2023). While offering opportunities, their use in education raises concerns about limiting student growth. As noted in the white paper, LLMs perform near human levels on assessments (Zellers et al., 2019; Sakaguchi et al., 2019; Chen et al., 2021), making detection essential for instructors to guide appropriate usage.
Fundamentals of AI Writing Detection
Detecting AI-generated writing relies on identifying statistical anomalies that distinguish it from human text. LLMs generate tokens sequentially from probability distributions, resulting in more consistent and formulaic structures compared to human writing, which is often more varied and creative.
Key concepts include perplexity and burstiness (Gehrmann et al., 2019). Perplexity measures the “smoothness” of word sequences—AI text tends to have lower perplexity due to predictable token choices. Burstiness assesses variations in sentence length and structure, where human writing shows greater deviation. Beyond these, detection systems capture long-range statistical dependencies to differentiate origins.
Research highlights that while LLMs mimic human writing, they leave detectable signals. Turnitin’s system leverages these to provide visibility, helping educators foster critical thinking without outright banning AI tools.
Turnitin’s AI Detection Solution: An Overview
Turnitin serves over 16,000 institutions in 185 countries, processing more than 250 million submissions as of June 2024. Launched in April 2023 with the AIW-1 model, the system evolved to AIW-2 in December 2023 for better detection of paraphrased AI text, and AIR-1 in July 2024 for AI paraphrase identification.
The architecture integrates AIW-2 (AI Writing detection) and AIR-1 (AI Rewriting detection). AIW-2 first classifies text as human or AI-generated. If 20% or more is AI, AIR-1 checks for paraphrase signatures, highlighting such sentences in purple in reports. This threshold minimizes false positives (FPR below 1%).
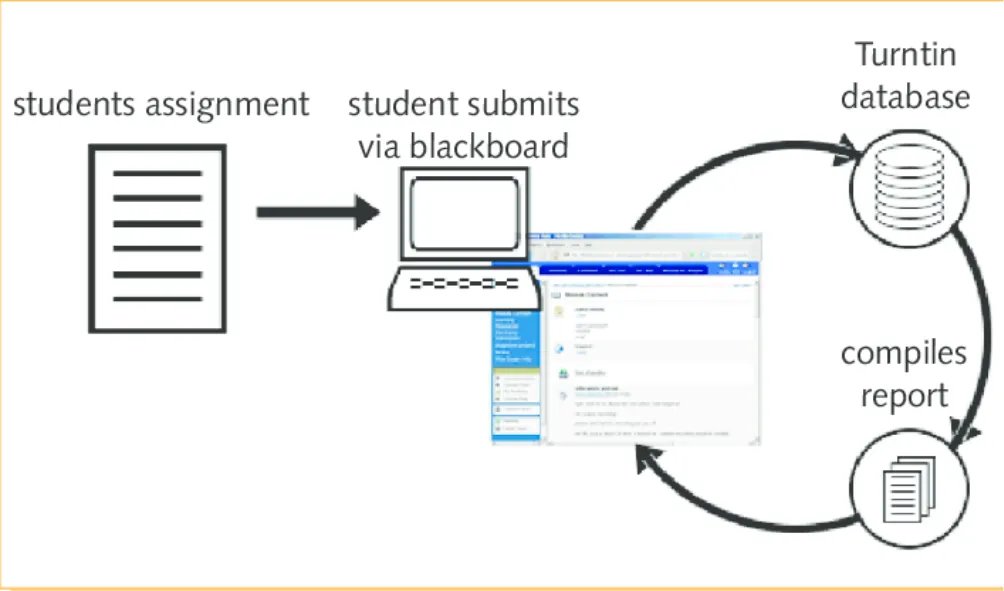
The system requires documents of at least 300 words for stability. Independent studies confirm its efficacy, with zero false accusations in comparisons (Weber-Wulff et al., 2023; Walters, 2023; Liu et al., 2024). For more on Turnitin’s tools, visit www.turnitin.com.
Deep Learning Framework: AIW-2 and AIR-1
Both models use transformer-based deep learning, outperforming simpler metrics like perplexity alone. AIW-2 trains on diverse datasets including AI-generated and authentic academic writing spanning geographies and subjects. A key enhancement over AIW-1 is incorporating “AI+AI paraphrased” text, improving detection of manipulated content.
Datasets mirror real-world scenarios, minimizing bias by including underrepresented groups like English Language Learners (ELLs) and niche subjects (e.g., anthropology). Training involves complex prompts, from full essays to mixed human-AI-paraphrased texts.
The model processes text in sliding windows of ~200-300 words (5-10 sentences), outputting a score from 0 (human-like) to 1 (AI-like). Sentence-level scores aggregate via weighted averages, compared to thresholds for classification. AIR-1 uses a similar framework but focuses on paraphrase signatures, which differ from standard LLM generation.
This flexibility allows capturing subtle patterns, as transformers model nonlinear token associations better than hand-curated features.
Testing and Evaluation Protocols
Turnitin prioritizes recall (efficacy in detecting AI) and FPR (reliability in avoiding mislabels). Accuracy is avoided as it’s dataset-dependent and manipulable.
For AIW-2, FPR was tested on 719,877 pre-2019 human-written papers, yielding 0.51% document-level and 0.33% sentence-level—improvements over AIW-1’s 0.70% and 0.42%.
Recall used a 2,970-document dataset mixing human, AI, and hybrids, achieving 91.18% document-level (vs. AIW-1’s 89.83%) and 95.06% sentence-level (vs. 91.22%). On 1,768 AI-paraphrased documents, AIW-2’s recall jumped to 78.34% from AIW-1’s 51.7%.
| Metric | Dataset | AIW-1 | AIW-2 |
|---|---|---|---|
| Document FPR | Pre-2019 Human | 0.70% | 0.51% |
| Sentence FPR | Pre-2019 Human | 0.42% | 0.33% |
| Document Recall | Standard | 89.83% | 91.18% |
| Sentence Recall | Standard | 91.22% | 95.06% |
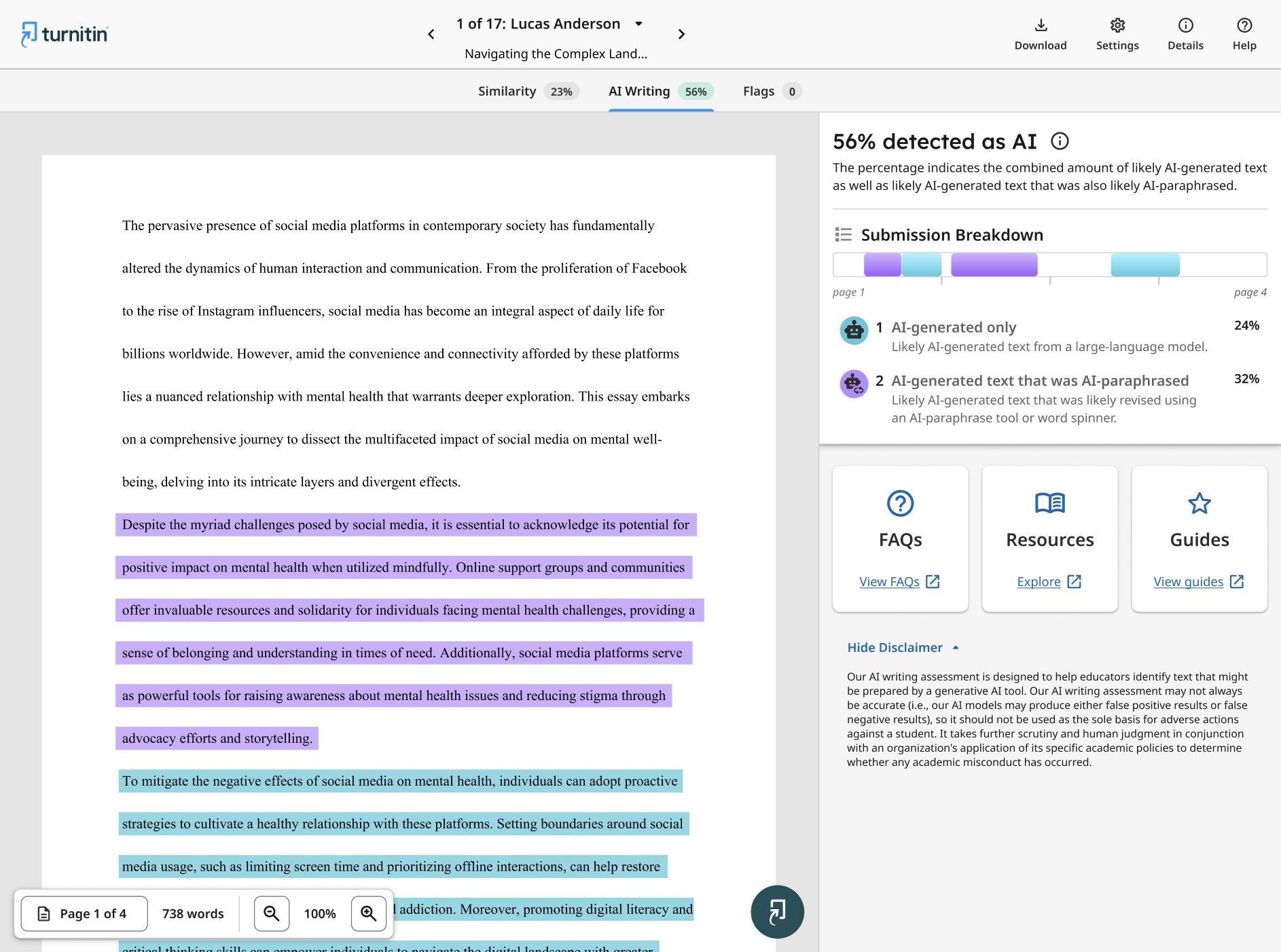
For AIR-1, metrics focus on misidentification: Type 1 (falsely labeling non-paraphrased AI as paraphrased) at 2.91%, and Type 2 (missing paraphrased AI) at 9.01%. The combined system correctly identifies AI-paraphrased sentences 81.68% of the time.
AIW-2 also improves detection across LLMs: 76.8% for GPT-4 (vs. 39.7%), 99.2% for Llama-2 (vs. 99.4%), and 87.25% for Gemini Pro 1.0.
Addressing Bias in English Language Learners
Bias testing on ~9,000 ELL documents (ASAP, ICNALE, PELIC datasets; Shermis et al., 2014; Ishikawa et al., 2023; Juffs et al., 2020) showed no significant differences. AIW-2’s FPR for L2 (ELL) writers is 0.86%, and for L1 (native) is 0.87%—statistically overlapping via bootstrap resampling (Adamson, 2023).

This ensures fairness, crucial for diverse educational settings.
Future Developments and Non-English Support
Turnitin commits to ongoing improvements, including non-English detectors using similar architectures but tailored tokenizers and datasets. These aim for <1% FPR and high recall, with language classifiers selecting models.
The white paper emphasizes Turnitin’s role in navigating AI’s academic impact, promoting integrity while embracing innovation.
In conclusion, Turnitin’s AI detection balances efficacy and reliability, empowering educators. As AI evolves, such tools will be vital. For the full white paper, visit Turnitin’s resources.
References
- Turnitin AI Technical Staff. (2024). Turnitin’s AI Writing Detection Model Architecture and Testing Protocol. www.turnitin.com.
- OpenAI. (2023). GPT-4 Technical Report.
- Vaswani et al. (2017). Attention is All you Need. Advances in Neural Information Processing Systems.
- Gehrmann et al. (2019). GLTR: Statistical Detection and Visualization of Generated Text. ACL Proceedings.
- Weber-Wulff et al. (2023). Testing of Detection Tools for AI-Generated Text. European Network for Academic Integrity.
- And other references as cited in the white paper.